Building Blocks
No more PRIVATE data leakage: Inonyma Data De-Identifier
In today’s fast-paced digital landscape, data reigns supreme as a catalyst for innovation, but privacy concerns still loom large as significant obstacles. Organizations find themselves in a precarious position, owning vast troves of valuable data but hesitating to use it due to stringent privacy constraints. This hesitance is especially pronounced when dealing with Large Language Models (LLMs), where employees might inadvertently share sensitive information about people or the organization itself.
Several unresolved issues amplify the reluctance of employers and stakeholders to fully embrace LLMs:
- There is a lack of explicit consent from data subjects,
- Data often remains unanonymized, increasing the risk of exposure,
- Fear persists that LLM providers repurpose the shared data,
- There is a strong desire to maintain control over proprietary information,
- Monitoring actual employee use of these AI tools proves difficult.
Concerns about data privacy are everywhere:
- In text, when detailing an employee situation by mentioning their name or referring to the organization’s management,
- When sharing documents, such as court decisions, legally forwarded to a lawyer,
In structured formats like JSON or xAPI, where every step of a learner’s journey can be traced, - In emails containing sensitive client discussions,
- In digital communications highlighting strategic business plans.
Trust is vital for successful data exchanges with third party tools or organizations. Data spaces offer the perfect infrastructure to exchange data among trusted partners. Protecting personal data is not just a regulatory box to tick, it’s foundational to achieving data sovereignty. Without addressing these privacy concerns, organizations cannot fully harness innovation’s potential or engage in collaborative ventures with confidence.
Challenge solved with Inonyma Data De-Identifier
The Inonyma Data De-Identifier stands as a technology in the realm of data protection, crafted to convert sensitive information into secure, usable data sets. At its core, this tool addresses the critical need for privacy by enabling the automatic detection and anonymization (or pseudonymization) of Personally Identifiable Information (PII) across a variety of data formats. Whether dealing with plain text, complex JSON structures, or extensive documents, organizations can seamlessly integrate this technology to safeguard privacy without sacrificing data utility.
What sets the Inonyma Data De-Identifier apart is its great flexibility designed to address diverse data handling needs, through robust anonymization processes:
- Replace: Automatically substitutes sensitive information with generic placeholders, maintaining data structure while eliminating identifiable elements.
- Redact: Conceals PII by blanking it out within documents, while preserving the document’s context without exposing sensitive details.
- Mask: Partially hides information, like displaying only the last four digits of a credit card number, useful for balancing privacy and functionality.
- Hash: Converts data into fixed-length hash codes
- Encrypt: Employs cryptographic techniques to securely transform data, which can only be decrypted by authorized parties, enhancing data security during storage and transfer.
This adaptability not only ensures uncompromising data privacy but also facilitates crucial processes such as secure analytics and AI training. By transforming sensitive datasets into privacy-compliant resources, organizations can confidently perform data analysis, enabling insightful business intelligence and innovation without the looming threat of privacy breaches.
In addition to internal data processing, the Inonyma Data De-Identifier empowers organizations to engage in safe data sharing. Secure, anonymized datasets can be exchanged across departments or even with external partners, promoting collaboration and enhancing operational efficiency while firmly adhering to compliance standards.
Inonyma Data De-Identifier is more than a tool—it’s a strategic enabler for any organization seeking to harness data capabilities while maintaining the highest standards of privacy and data protection.
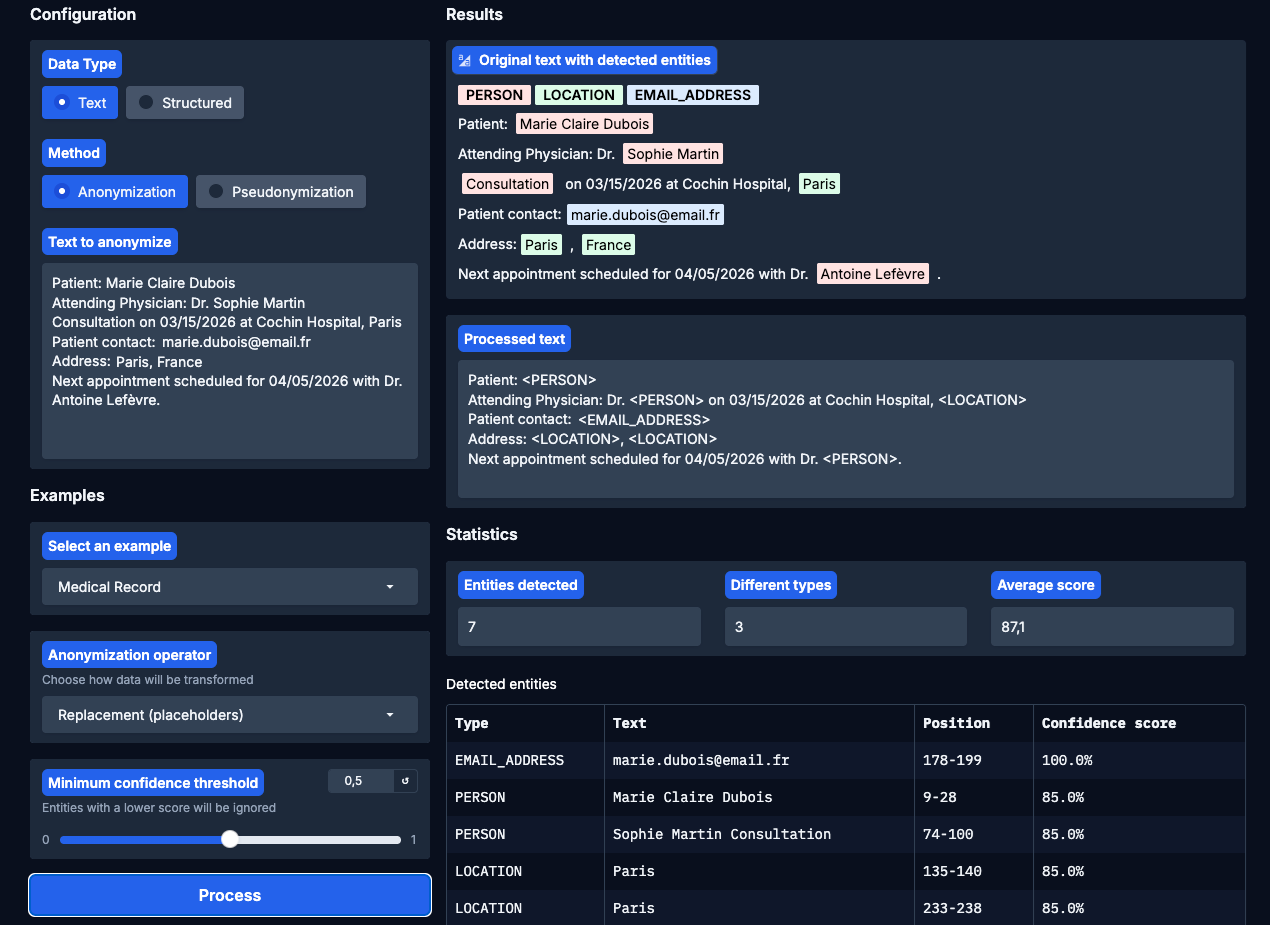
Screen of an interface of the Inonyma Data De-Identifier tool
Case study : Personalizing learning pathways with Inonyma’s Data De-Identification tool
In this scenario, we deployed Inonyma’s data de-identification tool as part of a project aimed at generating personalized learning paths for vocational students. The project includes five Accredited Training Organizations (Organismes de Formation Accrédités) with more than 3000 students per year.
The process begins with learners participating in an initial positioning test designed to gather crucial insights into their current skills, needs and goals. Given the open-text nature of the response fields, learners can include whatever information they choose to share, which often contains personal data.
To preserve the learners’ privacy while maximizing data value, we offered to utilize Inonyma Data De-Identifier (DDI) to anonymize all test responses. This ensures any personally identifiable information is stripped from the data before it is passed on for further analysis.
Once the responses are anonymized, they are structured and fed into a Large Language Model (LLM) through a crafted prompt. The LLM then analyzes the profiles and identifies key areas for focus and attention. This analysis reveals potential learning gaps, strengths, and areas requiring further development.
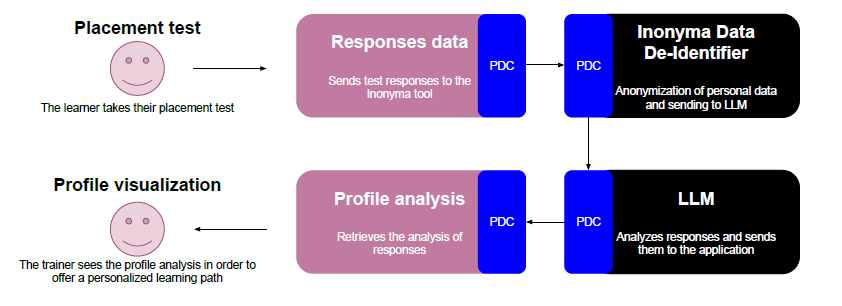
Data flow of the case study
The outcome of this entire process is the ability to propose the most suitable personalized learning path for each individual. By respecting data privacy, the organization can confidently use AI-driven insights to enhance the educational experience, ultimately leading to more effective and targeted training programs tailored to each learner’s unique profile.
Stakeholder Value
Sensitive data is present in many organizational processes. We will detail some possible use cases for the tool.
Using LLMs and AI
Organizations today are eager to leverage the immense capabilities of Large Language Models (LLMs) for tasks ranging from customer service inquiries to advanced problem-solving. However, the use of LLMs often involves sharing sensitive information, which presents significant privacy risks, especially when considering the absence of explicit consent and the potential for data misuse. With Inonyma’s data de-identifier, sensitive information embedded within datasets or texts, such as customer inquiries or internal notes, can be effectively anonymized before being processed by LLMs. This ensures the data retains its intrinsic value while mitigating the risk of exposing private information.
The result? Employees can engage with LLMs confidently, harnessing their full potential without the fear of leaking confidential data. The tool facilitates a secure environment for AI utilization by anonymizing sensitive content, thus preventing data breaches and maintaining compliance with privacy regulations. This approach transforms potential privacy threats into opportunities for safe and innovative use of AI technologies across the organization.
Analysis of a student profile
Educational institutions are increasingly accumulating vast amounts of sensitive student data essential for enhancing learning experiences and educational research. However, stringent compliance requirements, such as those established by National and European regulations, make sharing this data a complex and challenging task. By leveraging Inonyma’s data de-identifier, institutions can swiftly pseudonymize student records, preserving data coherence while safeguarding individual privacy. This process maintains the intrinsic value of the data for analysis and research without risking exposure of personal information.
The result? Educational organizations can securely share and analyze data in compliance with privacy standards, fostering innovations in educational strategies and tools.
Shared medical record
Healthcare providers are faced with enormous amounts of sensitive patient data needed for research. Due to strict compliance requirements imposed by regulations such as HIPAA, sharing this data becomes difficult. With Inonyma’s data de-identifier, medical records are quickly anonymized, preserving data integrity while ensuring confidentiality.
The result? Secure, compliant data sharing that facilitates advances in medical research, transforming potential liabilities into research assets in a matter of minutes.
Future perspective
As we look forward, the scalable data ecosystems enabled by Inonyma and other data spaces services promise unprecedented collaboration. By safely integrating additional building blocks like AI assessments and visualizations, we open doors to innovations previously constrained by fear and privacy risks. Once organizations embrace safe data circulation, new possibilities emerge, enabling industries to drive growth, improve services, and innovate fearlessly while respecting privacy rights.
Want to learn more about Inonyma? Subscribe or request a demo!
What are Building Blocks?
Prometheus-X’s “Building Blocks” are open-source, modular components designed to facilitate the creation of secure, interoperable, and human-centric data spaces, particularly in sectors like education and skills. These building blocks support both personal and non-personal data management, aligning with European data strategies and regulations such as GDPR.



